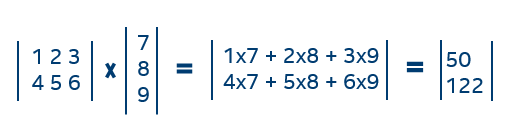今年春天,gratianlup在他的博客中描述了 Visual Studio 2019中的C++游戏开发 . 从VisualStudio2019版本16.0到VisualStudio2019版本16.2,我们做了更多的改进。上 渗透者演示 我们在游戏中CPU最密集的部分赢得了2–3%的性能胜利。
一个巨大的吞吐量提高了链接器!查看我们最近在 Visual Studio 2019中改进的链接器基础知识 .
新的和改进的C++编译器优化的全面列表可以在最近的博客帖子中找到。 Visual Studio 2019版本16.2中的MSVC后端更新 . 我将更详细地谈谈其中的一些。
以下所有示例都是为使用这些开关的x64编译的:/arch:AVX2 /O2 /fp:fast/c/Fa。
基于AVX的微小完美归约环矢量化
这是确保两个向量不会偏离太多的常见模式:
#include <xmmintrin.h>
#include <DirectXMath.h>
uint32_t TestVectorsEqual(float* Vec0, float* Vec1, float Tolerance = 1e7f)
{
float sum = 0.f;
for (int32_t Component = 0; Component < 4; Component++)
{
float Diff = Vec0[Component] - Vec1[Component];
sum += (Diff >= 0.0f) ? Diff : -Diff;
}
return (sum <= Tolerance) ? 1 : 0;
}
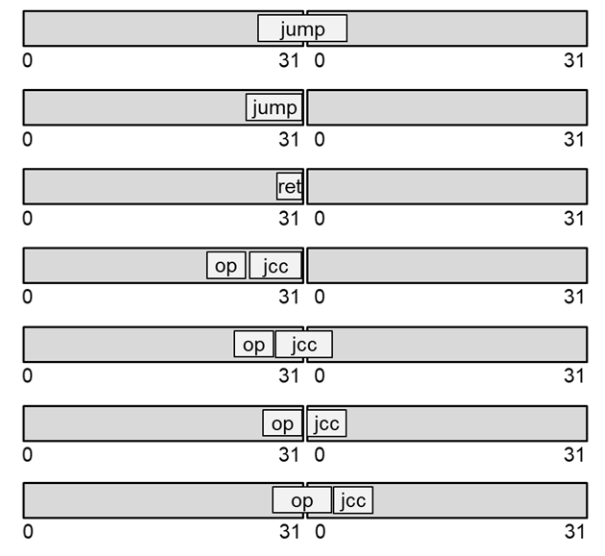
对于版本16.2,我们调整了AVX架构的矢量化启发式算法,以更好地利用硬件功能。反汇编适用于x64、AVX2,左侧为旧代码,右侧为新代码:
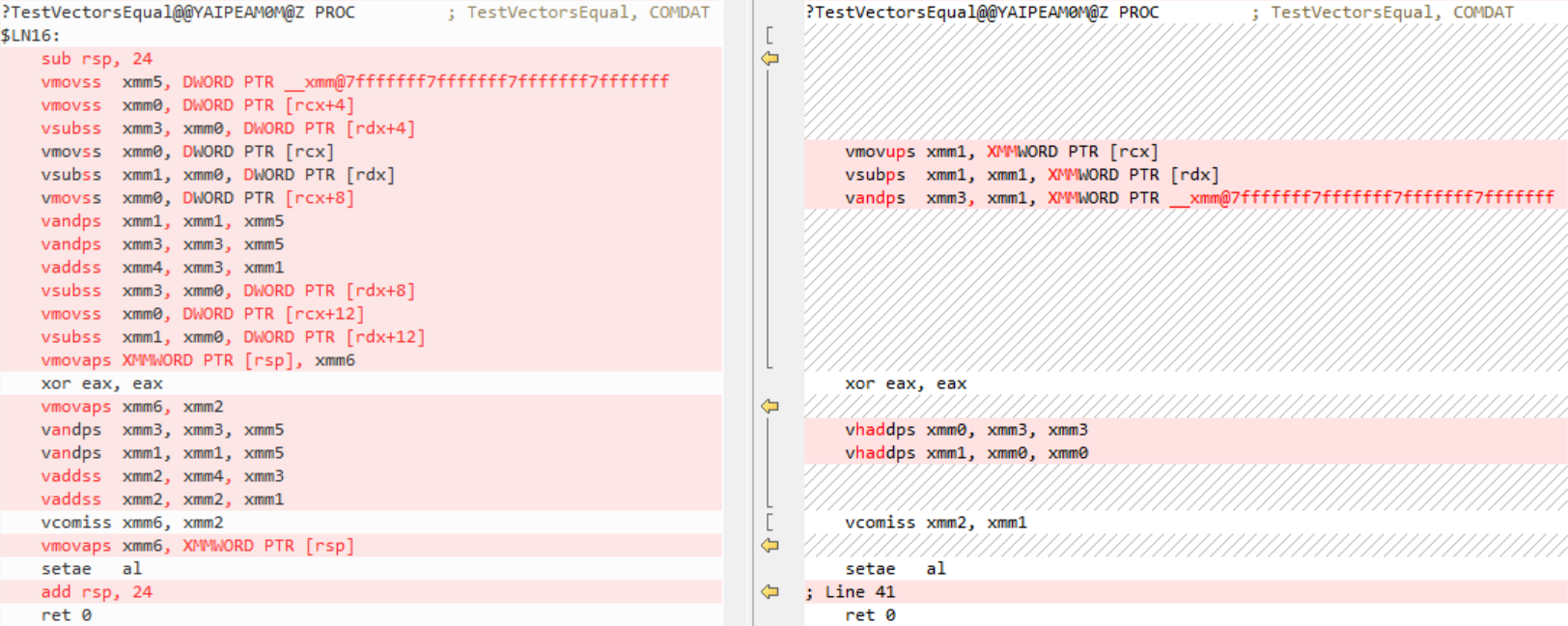
VisualStudio2019版本16.0将循环识别为还原循环,没有对其进行矢量化,而是将其完全展开。版本16.2还将循环识别为还原循环,将其矢量化(由于启发式的变化),并使用水平加法指令来获得总和。因此,现在的代码更短更快。
单个矢量元的内禀识别
编译器现在在优化向量内部函数方面做得更好了,它只处理最低的单个元素(那些后缀为ss/sd的元素)。
改进的代码的一个很好的例子是平方根逆。此函数取自Unreal引擎数学库(为简洁起见,删除了注释)。基于虚幻引擎的所有游戏都使用它来渲染对象:
#include <xmmintrin.h>
#include <DirectXMath.h>
float InvSqrt(float F)
{
const __m128 fOneHalf = _mm_set_ss(0.5f);
__m128 Y0, X0, X1, X2, FOver2;
float temp;
Y0 = _mm_set_ss(F);
X0 = _mm_rsqrt_ss(Y0);
FOver2 = _mm_mul_ss(Y0, fOneHalf);
X1 = _mm_mul_ss(X0, X0);
X1 = _mm_sub_ss(fOneHalf, _mm_mul_ss(FOver2, X1));
X1 = _mm_add_ss(X0, _mm_mul_ss(X0, X1));
X2 = _mm_mul_ss(X1, X1);
X2 = _mm_sub_ss(fOneHalf, _mm_mul_ss(FOver2, X2));
X2 = _mm_add_ss(X1, _mm_mul_ss(X1, X2));
_mm_store_ss(&temp, X2);
return temp;
}
同样,x64,AVX2,左边是旧代码,右边是新代码:
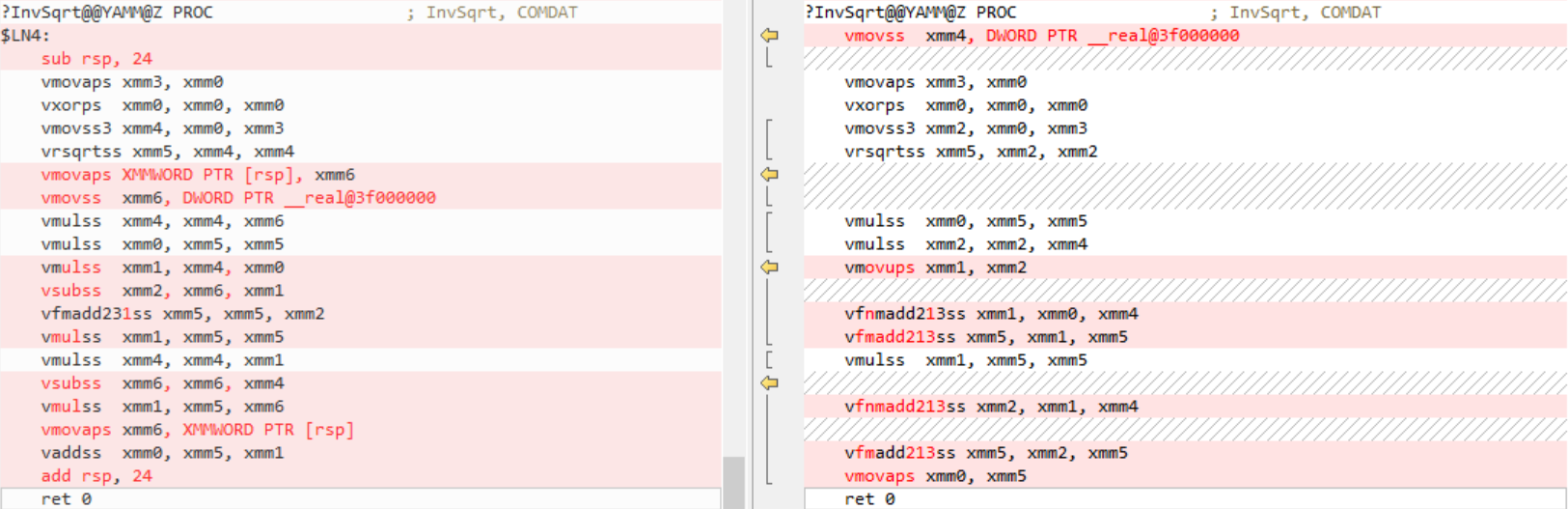
VisualStudio2019版本16.0为所有内部函数逐个生成代码。版本16.2现在更好地理解了内部函数的含义,并且能够将乘法/加法内部函数组合到FMA指令中。在这方面仍有一些改进需要改进,有些针对的是版本16.3/16.4。
即使现在,如果给定const参数,此代码也将完全是常量:
float ReturnInvSqrt()
{
return InvSqrt(4.0);
}
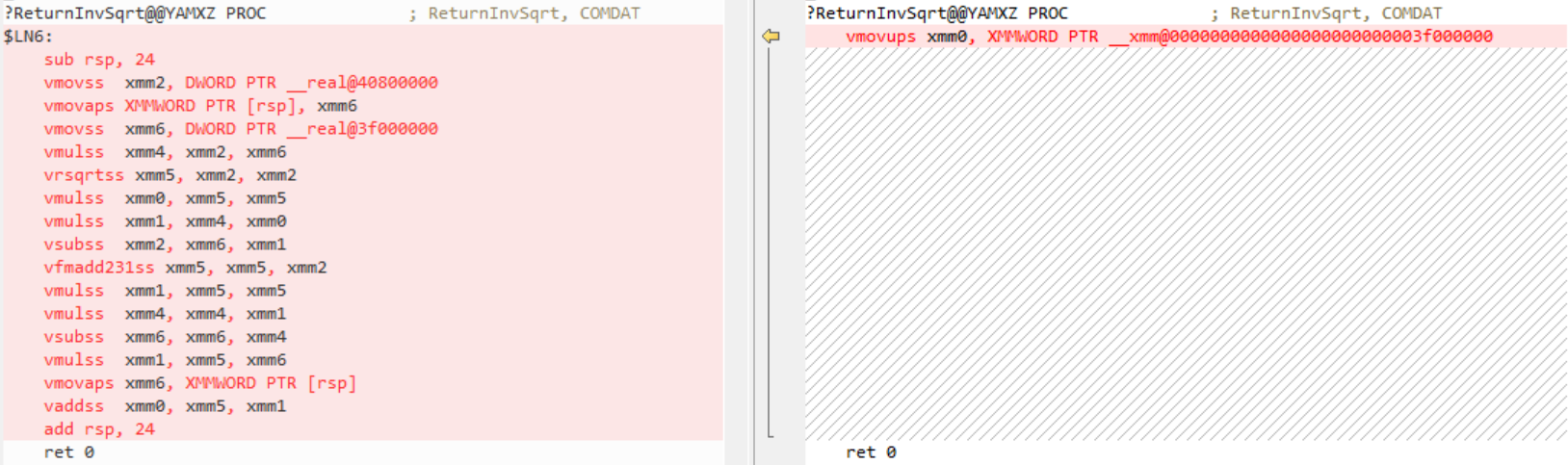
同样,VisualStudio2019版本16.0在这里为所有的内部函数逐个生成代码。版本16.2能够在编译时计算值(这是通过/fp:fast开关完成的。
更多FMA模式
编译器现在在更多情况下生成FMA:
(fma,b,(c*d))+x->fma,b,(fma c,d,x)x+(fma,b,(c*d))->fma,b,(fma c,d,x)
(a+1)*b->fma a,b,b(a+(-1))*b->fma,b,(-b)(a–1)*b->fma a,b,(-b)(a–(-1))*b->fma a,b,b(1–a)*b->fma(-a),b,b(-1–a)*b->fma(-a),b,-b
它还简化了FMA:
fma,c1,(a*c2)->fmul a*(c1+c2)fma(a*c1),c2,b->fma,c1*c2,bfma a,1,b->a+bfma a,-1,b->(-a)+b->b–afma-a,c,b->fma-c,bfma a,c,a->a*(c+1)fma a,c,(-a)->a*(c-1)
以前的FMA生成只适用于局部向量。在全球范围内也有所改进。
下面是一个优化的例子:
#include <xmmintrin.h>
__m128 Sample(__m128 A, __m128 B)
{
const __m128 fMinusOne = _mm_set_ps1(-1.0f);
__m128 X;
X = _mm_sub_ps(A, fMinusOne);
X = _mm_mul_ps(X, B);
return X;
}
左边是旧代码,右边是新代码:

FMA更短更快,常数完全消失,不会占用空间。
另一个示例:
#include <xmmintrin.h>
__m128 Sample2(__m128 A, __m128 B)
{
__m128 C1 = _mm_set_ps(3.0, 3.0, 2.0, 1.0);
__m128 C2 = _mm_set_ps(4.0, 4.0, 3.0, 2.0);
__m128 X = _mm_mul_ps(A, C1);
X = _mm_fmadd_ps(X, C2, B);
return X;
}
左边是旧代码,右边是新代码:

版本16.2正在简化:
fma(a*c1),c2,b->fma,c1*c2,b
常量现在在编译时被提取和相乘。
Memset与初始化
通过在适当的地方调用更快的CRT版本而不是内联扩展其定义,Memset代码生成得到了改进。存储由相同字节组成的常量值的循环(例如0xABABABAB)现在也使用memset的CRT版本。 与na相比ï在SSE2上调用memset的代码生成速度至少快2倍,在AVX2上甚至更快。
内联
我们对内联启发式算法做了更多的调整。它们被修改为对包含控制流的小函数进行更积极的内联。
新的优化得到了回报。
我们运行了 渗透者演示 再次(参见关于 Visual Studio 2019中的C++游戏开发 演示和测试方法的描述)。简短提醒:渗透演示是基于虚幻引擎,是一个真正的游戏很好的近似。游戏性能是通过帧时间来衡量的:越小越好(相反的指标是每秒帧数)。测试是类似于以前的测试运行,唯一的区别是新的硬件:这次我们运行的AMD禅2最新的处理器。
测试PC配置:
- AMD64 Ryzen 5 3600 6核处理器,3.6 Ghz,6核,12个逻辑处理器
- Radeon RX 550 GPU
- 16 GB内存
- 视窗10 1903
结果
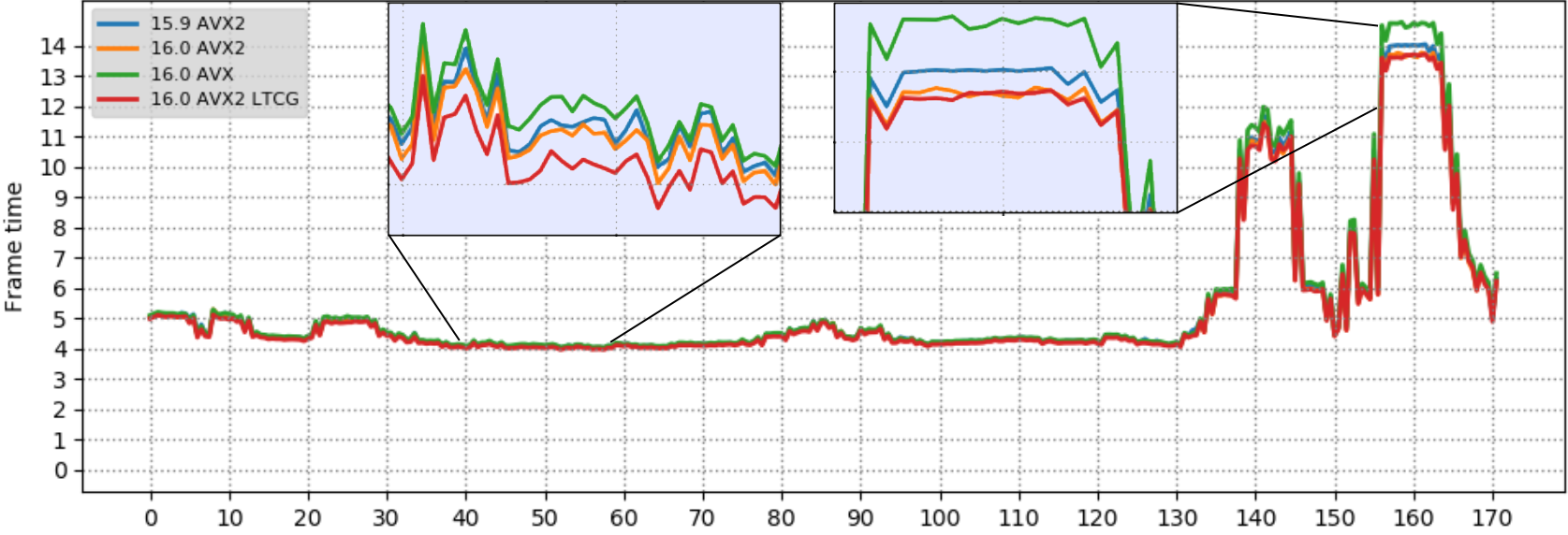
这次我们只测量了/arch:AVX2 configuration. 如前所述,越低越好。
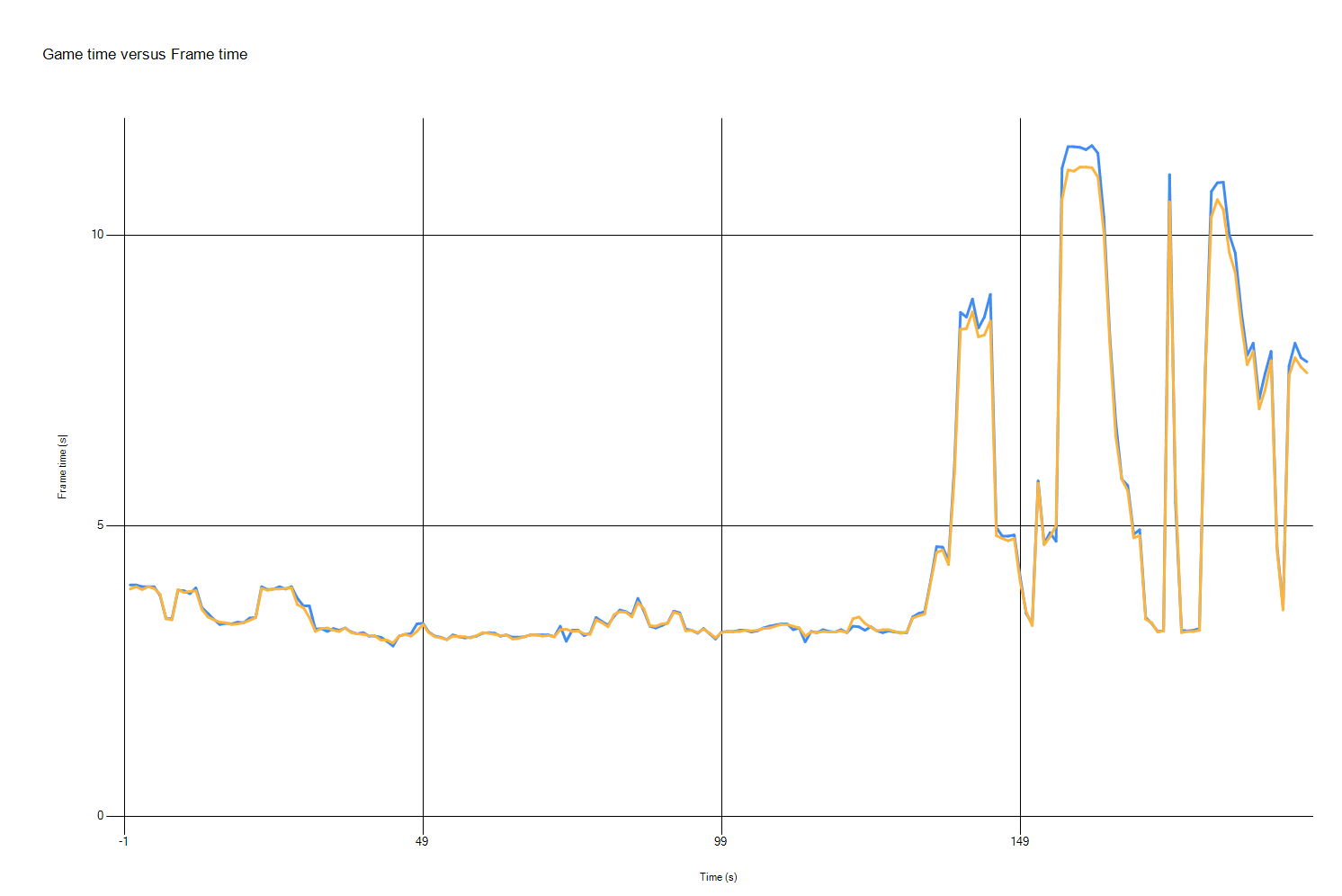
蓝线是用Visual Studio 2019编译的演示,黄线是用Visual Studio 2019版本16.2编译的。X轴-时间,Y轴-帧时间。
两次运行之间的帧时间基本相同,但在演示部分,使用Visual Studio 2019版本16.2时,帧时间最高(因此帧速率最低),我们得到了2–3%的改进。
我们希望你能 下载Visual Studio 2019 试试看。一如既往,我们欢迎您的反馈。我们可以通过下面的评论或电子邮件联系我们( visualcpp@microsoft.com ). 如果您在使用visualstudio或MSVC时遇到问题,或者有什么建议,请告诉我们 帮助>发送反馈>报告问题/提供建议 在产品中,或通过 开发者社区 . 你也可以在Twitter上找到我们( @视觉 ).

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)