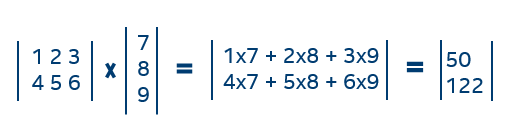在visualstudio2019版本16.2中,我们改进了几个标准库函数的codegen。以您对开发者社区的反馈为指导( 内联标准::lldiv 和 std::fmin、std::fmax、std::round、std::trunc的改进codegen )我们关注标准部门的变体( std::div , std::ldiv , std::lldiv )以及 std::isnan .
最初,对标准库的函数调用,而不是内联汇编指令,是在每次调用 std::div 和 std::isnan ,而不考虑传递的编译器优化标志。由于这些标准库函数定义位于运行时内部,因此它们的定义对编译器来说是不透明的,因此不是内联和优化的候选对象。此外,调用这两个 std::div 和 std::isnan 大于这些操作的实际成本。在大多数平台上, std::div 可以在返回商和余数的单个指令中计算 std::isnan 只需要比较和条件标志检查。内联这些调用将消除函数调用开销,并允许进行优化,因为编译器具有调用函数的附加上下文。
为了支持内联汇编代码生成,我们添加了许多不同的函数作为 std::isnan , std::div ,还有朋友。注册一个内在函数可以有效地向编译器“传授”该函数的含义,并对生成的代码产生更好的控制。我们使用codegen解决方案,而不是库更改,以避免更改库头。
优化std::div和朋友
MSVC编译器预先支持优化裸除法和余数运算。因此,要向 std::div 我们认识到 std::div 作为编译器内部函数,然后将已识别调用的输入转换为编译器期望的除法和余数操作的规范格式。
优化std::isnan
替换对的呼叫 std::isnan 由于C和C++标准的矛盾要求,我们所要的两类功能比较复杂。根据C标准, isnan 以及它所包装的功能, fpclassify 需要实现为宏,而C++要求两个操作都要实现为函数重载。下面是C++中VS结构的调用结构,其中需要在Blue Blue框中实现函数重载,需要在虚线的紫色框中实现宏,而不需要绿色的宏。
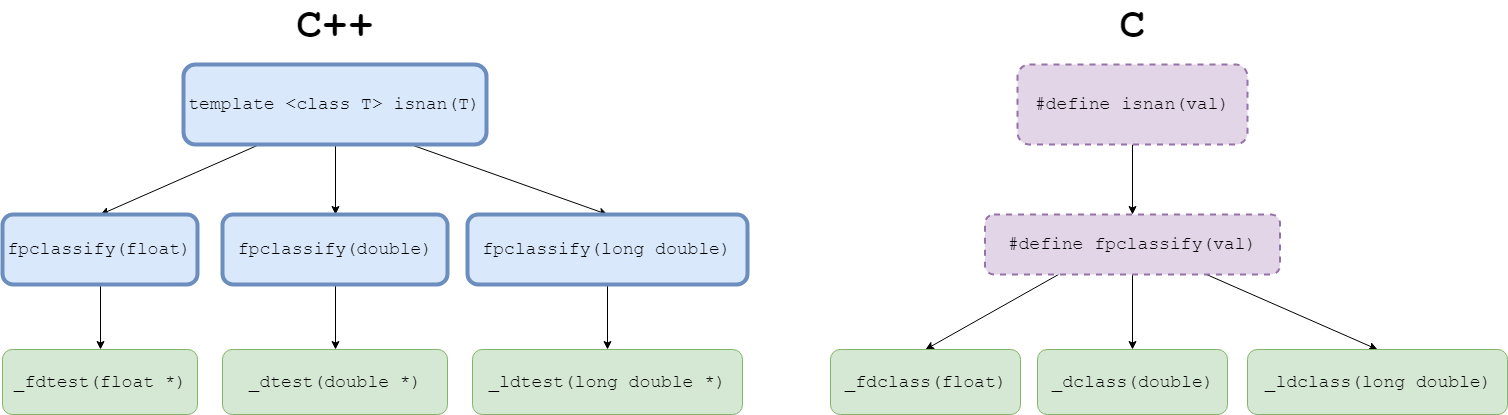
为了获得C和C++代码的统一解决方案,我们必须绕过两者。 std::isnan 和 std::fpclassify 看看函数 std::fpclassify 包裹。我们选择绿色函数注册为编译器内部函数,因为它们没有任何实现需求。另外,由于任一标准中的每个重载都完成相同的任务,所以我们可以将一个标准的内联(C++选择的)实例转换为添加的C本质的实例。下表展示了统一过程的结果,该过程将我们在初始传递之后操作的内部函数从6个减少到3个。
| 功能 | 内在函数 | 统一后内在的 |
_fdtest |
IV__FDTEST |
IV__FDCLASS |
_dtest |
IV__DTEST |
IV__DCLASS |
_ldtest |
IV__LDTEST |
IV__LDCLASS |
_fdclass |
IV__FDCLASS |
IV__FDCLASS |
_dclass |
IV__DCLASS |
IV__DCLASS |
_ldclass |
IV__LDCLASS |
IV__LDCLASS |
回到 std::isnan . 添加六个新的编译器内部函数的原因是为了改进 std::isnan . 但是,在我们转换了 std::fpclassify 调用,实际上并没有改变 std::isnan . 在 _dclass 例如,我们已经认识到 _dclass 作为内部函数调用,但是我们不会更改为 _dclass ,发出的代码仍然是对 _dclass 我们刚开始的时候。
识别所需的最后一步 std::isnan 作为一个内在的,因此使更有效的代码生成涉及模式匹配。检查float/double/etc.是否为NaN,如下所示:
isnan(double x) {
return FP_NAN == IV__DCLASS(x);
}
在哪里? FP_NAN 是C和C++标准中定义的常数。现在很容易识别呼叫 _dclass 朋友们,优化器被扩展以识别上述模式(调用三个统一的内部函数之一,然后与 FP_NAN 常量)并将其转换为新的 std::isnan 内在的, IV_ISNAN .
结果
为了更好地说明codegen的差异,下面是两种代码的不同x64代码生成的示例 std::isnan 和 std::div .
标准::isnan(双)
| 参考 | 具有内在性 |
lea rcx, QWORD PTR _X$[rsp]
|
ucomisd xmm0, xmm0
|
标准::div(长,长)
| 参考 | 具有内在性 |
mov edx, ebx
|
mov eax, esi
|
有效内联这些调用对性能有多大影响?当通过调用1的每个成员上的每个操作进行基准测试时×10 9 对于未知输入的元素数组,可以观察到以下改进:
| 标准::isnan(双) | 参考 | 具有内在性 | %%改进 |
| 平均值 | 4.03 | 1.25 | 69%% |
| 标准偏差 | 0.05 | 0.04 |
| 标准::div(长,长) | 参考 | 具有内在性 | %%改进 |
| 平均值 | 6.52 | 6.06 | 7%% |
| 标准偏差 | 0.11 | 0.04 |
您可以查看基准源代码 在这里 在编译器资源管理器上。每个基准测试都在intelxeoncpuv3@3.50GHz上运行了6次,第一次是预热运行。
结论
通过升级到在/O2下编译的代码库中的16.3工具集,可以透明地启用上述优化。否则,请确保显式使用/Oi来启用内部支持。
C++团队已经在展望未来版本中提高标准库函数的性能,并对其进行类似的优化。 std::fma 以16.4版本为目标。一如既往,我们欢迎您的反馈和进一步改进codegen的功能请求。如果您看到代码生成效率低下的情况,请通过下面的评论或在上打开一个问题联系我们 D 伊夫勒 C 社区 .

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)