在VisualStudio 2019版本16.2中,我们继续改进C++后台,并通过生成吞吐量的改进和新的和改进的优化。这些是建立在我们的 Visual Studio 2019版本16.0中的MSVC后端改进 这是我们之前宣布的。我们将通过他们自己的博客文章来跟进许多改进。
null
构建吞吐量改进
- 链接器的改进将大型项目中调试信息的迭代构建时间提高了3倍(或更多)(显示的数字是针对不真实的发动机装运配置)
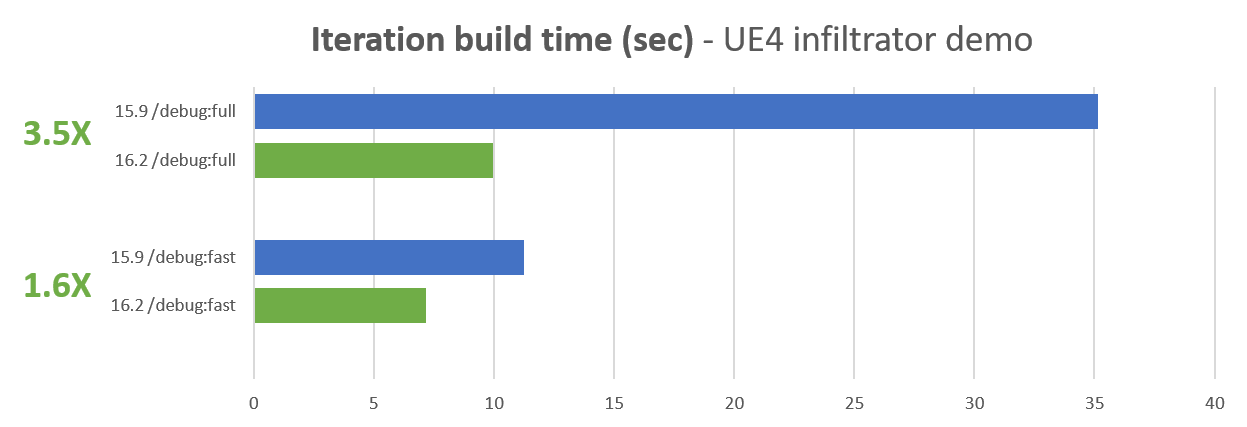
- 链接时间也提高了2倍。
新的和改进的优化
内联线改进
- 如果小函数中有一个分支并且是从循环中的分支调用的,那么它将更多地内联。
改进的代码生成和内部函数优化
- 消除了一些常见数学函数的开销( 标准::伊斯南 , 标准::ldiv , 标准::lldiv )用内联汇编指令替换函数调用。
- 对于x86/x64目标,优化器将识别一些只在最低元素上工作的向量内部函数,并对它们进行优化,包括构建FMA(fused multiply add)和执行常量折叠。
矢量器改进
- 微小的缩减循环(小于12次迭代)将被矢量化 /arch:AVX 如果元素完全符合向量的大小。
- 改进了当对循环的自动矢量化尝试失败时,为带有指针诱导变量的循环生成的代码序列。
新分析通过
- 改进了对控制流的分析,以删除可证明为真/假的更复杂的分支实例。
- 添加了新的流敏感限制指针分析。限制指针在可以转义的区域(即在当前作用域之外访问)中的处理方式将不同于安全用作“限制”指针的区域。
一般优化器改进
- 在按值返回多个对象的函数中启用复制省略。
- 改进了使用LTCG编译时指针减法的优化。指针减法包括一个除法,现在可以在某些情况下优化除法。
- 改进优化,为x86/x64平台生成和简化FMA指令。这包括为向量类型的全局变量启用FMA。
- C++ 20改进代码生成 宇宙飞船操作员 ,可在 /std:c++latest :比较中使用的已知值的更好的恒定传播(例如。 标准::强顺序::少 ),以及常量汇编指令结果的编译时计算。
- 通过在适当的地方调用更快的CRT版本而不是内联扩展其定义,改进了memset代码生成。存储由相同字节组成的常量值的循环(例如0xABABABAB)现在也使用memset的CRT版本。
- 优化优化以合并相同的异常处理状态,节省C++程序的大小。注意:这只适用于 框架处理程序4 ,这将成为Visual Studio 2019版本16.3中的默认设置。
我们希望你能 下载Visual Studio 2019 试试看。一如既往,我们欢迎您的反馈。我们可以通过下面的评论或电子邮件联系我们( visualcpp@microsoft.com ). 如果您在使用visualstudio或MSVC时遇到问题,或者有什么建议,请告诉我们 帮助>发送反馈> 报告问题 /提供建议 在产品中,或通过 开发者社区 . 你也可以在Twitter上找到我们( @视觉 )和Facebook(msftvisualcpp)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)