VisualStudio 2019中的C++编译器包含了一些新的优化和改进,它们旨在提高游戏的性能,并通过减少大型项目的编译时间来提高游戏开发者的生产力。虽然博客文章的重点是游戏行业,但这些改进适用于大多数C++应用程序和C++开发人员。
编译时间改进
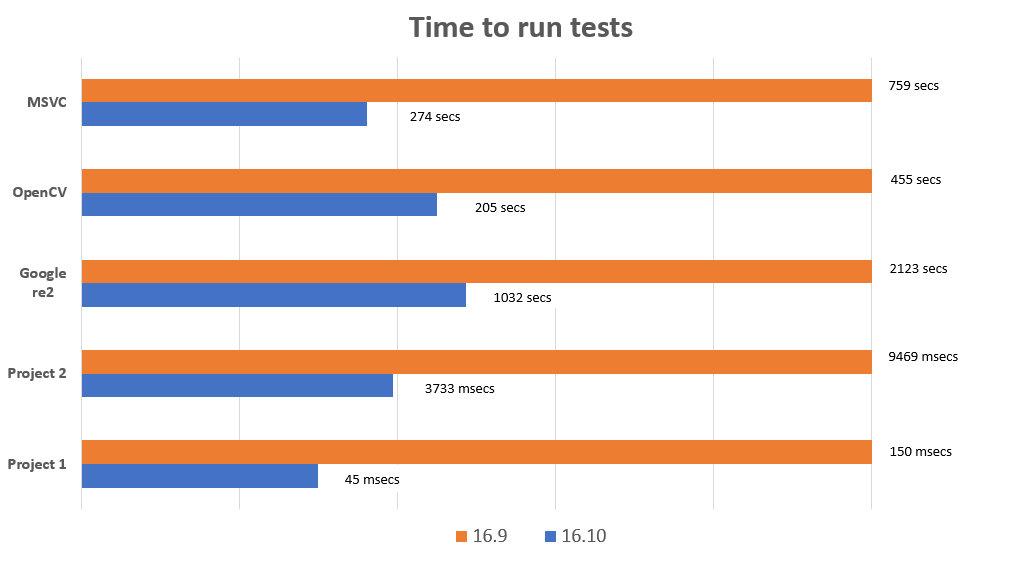
VS 2019版本中C++工具集团队的一个重点是改进链接时间,这又允许更快的迭代构建和更快的调试。对链接器的两个重要更改有助于加快调试信息(PDB文件)的生成:
- 后端中的类型修剪将删除未被任何变量引用的类型信息,并减少链接器在类型合并期间必须执行的工作量。
- 通过使用快速哈希函数来识别相同的类型,从而加快类型合并。
下表显示了链接一款大型流行AAA游戏时测量的加速比:
|
调试生成 配置 |
链接时间(秒) 与2017年相比(15.9) | 链接时间(秒) 与2019年相比(16.0) | 链接时间加速 |
| /调试:完全 |
392.1 |
163.3 |
2.40倍 |
| /调试:fastlink | 72.3 | 31.2 |
2.32倍 |
更多细节和额外的基准可以在 此博客帖子 .
向量(SIMD)表达式优化
代码优化器中最重要的改进之一是处理向量(SIMD)内部函数,这既可以来自源代码,也可以作为自动向量化的结果。在VS2017及之前的版本中,大多数向量操作将通过主优化器,而不需要任何特殊处理,类似于函数调用,尽管它们表示为内部函数(编译器已知的特殊函数)。从VS2019开始,大多数涉及向量内部函数的表达式都像使用 SSA优化器 .
两个浮子(例如。 _添加 )和整数(例如。 _添加epi32 )支持针对SSE/SSE2和AVX/AVX2指令集的Intrinsic版本。执行的一些优化包括:
- 恒定折叠
- 算术简化,包括重新关联
- cmp、最小/最大、abs、提取操作的处理
- 将向量转换为标量运算
- 洗牌和打包操作的模式
其他优化(如公共子表达式消除)现在可以利用对加载/存储向量操作的更好理解,这些操作的处理方式与常规加载/存储类似。有几种初始化向量寄存器的方法可以识别,并且在表达式简化过程中使用这些值(例如。 _mmu集u ps、u mmu集u ps1、u mmu集u ps、u mmu集零u ps 对于浮点值)。
另一个重要的加法是当/arch:AVX2 compiler 使用标志–以前它只对标量浮点代码执行。这允许CPU计算表达式 a*b+c型 在更少的循环中,这在数学繁重的代码中是一个显著的加速,如下例所示。
下面的代码举例说明了使用/arch:AVX2 and 使用/fp:fast时表达式优化:
__m128 test(float a, float b) { __m128 va = _mm_set1_ps(a); __m128 vb = _mm_set1_ps(b); __m128 vd = _mm_set1_ps(-b);
// Computes (va * vb) + (va * -vb) return _mm_add_ps(_mm_mul_ps(va, vb), _ mm_mul_ps(va, vd)); }
|
不做任何简化;未生成FMA。 |
VS 2017年/arch:AVX2 /fp:快速 vmovaps xmm3, xmm0 vbroadcastss xmm3, xmm0 vxorps xmm0, xmm1, DWORD PTR __xmm@80000000800000008000000080000000 vbroadcastss xmm0, xmm0 vmulps xmm2, xmm0, xmm3 vbroadcastss xmm1, xmm1 vmulps xmm0, xmm1, xmm3 vaddps xmm0, xmm2, xmm0 ret 0 |
| 未进行简化-根据/fp:precise不合法;FMA生成。 | 与2019年相比/arch:AVX2 vmovaps xmm2, xmm0 vbroadcastss xmm2, xmm0 vmovaps xmm0, xmm1 vbroadcastss xmm0, xmm1 vxorps xmm1, xmm1, DWORD PTR __xmm@80000000800000008000000080000000 vbroadcastss xmm1, xmm1 vmulps xmm0, xmm0, xmm2 vfmadd231ps xmm0, xmm1, xmm2 ret 0 |
| 整个表达式简化为“return 0”,因为/fp:fast允许应用通常的算术规则。 | 与2019年相比/arch:AVX2 /fp:快速
|
更多的例子可以在这个古老的网站上找到 博客文章 ,它讨论了几个编译器的SIMD生成—VS2019现在按预期处理所有情况,还有更多!
矢量优化的基准测试
为了衡量矢量优化的好处,Xbox ATG(Advanced Technology Group)提供了一个基于Unreal Engine 4代码的基准,用于常见的数学运算,如SIMD表达式、矢量/矩阵变换和sin/cos/sqrt函数。这些测试是值为常量的情况和值在编译时未知的情况的组合。这测试了编译时不知道值的常见场景,但也测试了内联之后通常出现的情况,即某些值变成常量。
下表显示了分为四个类别的测试的加速比,执行时间(毫秒)是该类别中所有测试的总和。下表显示了使用未知随机值时几个单独测试的改进–使用常量的版本现在按预期折叠。
|
类别 |
VS 2017(毫秒) | VS 2019(毫秒) |
加速 |
| 数学 | 482 | 366 | 27.36%% |
| 矢量 | 337 | 238 | 34.43%% |
| 矩阵 | 3168 | 3158 | 0.32%% |
| 三角学 | 3268 | 1882 | 53.83%% |
|
试验 |
VS 2017(毫秒) | VS 2019(毫秒) |
加速 |
|
矢量点3 |
42 |
39 |
7.4%% |
|
矩阵乘法 |
204 |
194 |
5%% |
|
向量 |
421 |
402 |
4.6%% |
|
标准化QRT |
82 |
77 |
7.4%% |
| 规范化InvSqrt |
106 |
97 |
8.8%% |
改进虚幻引擎4-渗透演示
为了确保我们的努力有益于实际游戏,而不仅仅是微观基准,我们使用了 渗透者演示 作为一款基于虚幻引擎4.21的AAA游戏的代表。大部分是实时呈现的电影序列,具有复杂的图形、动画和物理,执行模式类似于实际游戏;同时,它也是获得稳定的、可重复的结果的一个很好的目标,这些结果是研究性能和度量编译器改进的影响所必需的。
衡量游戏性能的主要方法是使用帧时间。帧时间可以看作FPS(每秒帧数)的倒数,表示准备显示一帧所需的时间,值越小越好。虚幻引擎的两个主要线程是游戏线程和渲染线程-这项工作主要集中在游戏线程的性能。
有四个版本正在测试,都是基于默认的Unreal引擎设置,使用 统一(巨型)建筑 和have/fp:fast/favor:AMD64 enabled. 请注意,正在使用AVX2指令集,但保留默认AVX的一个版本除外:
- 与2017年(15.9)相比/arch:AVX2
- 与2019年(16.0)相比/arch:AVX2
- 与2019年(16.0)相比/arch:AVX2 and /LTCG,展示其优势使用方法 链路时间代码生成
- 与2019年(16.0)相比/arch:AVX,以展示使用AVX2而不是AVX的好处
测试细节:
- 要捕获帧时间,自定义 ETW公司 提供者被集成到游戏中,以向用户报告值 Xperf公司 在后台运行。游戏的每个构建都有一个热身运行,然后在启用ETW跟踪的情况下运行整个游戏10次。每0.5秒计算一次最终帧时间,作为这10次运行的平均值。这个过程是由一个脚本自动执行的,这个脚本启动游戏一次,每次迭代后从一开始就重新启动关卡。在210秒(3:30米)长的演示中,前170秒被捕获。
- 测试PC配置:
- AMD Ryzen 2700x CPU(8核/16线程)固定在3.4Ghz,以消除动态频率缩放测量中的潜在噪声
- AMD Radeon RX 470 GPU
- 32 GB DDR4-2400内存
- Windows 10 1809
- 游戏的分辨率是640×480以减少GPU渲染的影响
结果:
下面的图表显示了四个测试版本的游戏到第170秒的测量帧时间。帧时间范围从4ms到15ms,在图形密集的部分大约是秒 155-165 . 为了使构建之间的差异更加明显,将放大“最快”和“最慢”部分。如前所述,帧时间值越低越好。
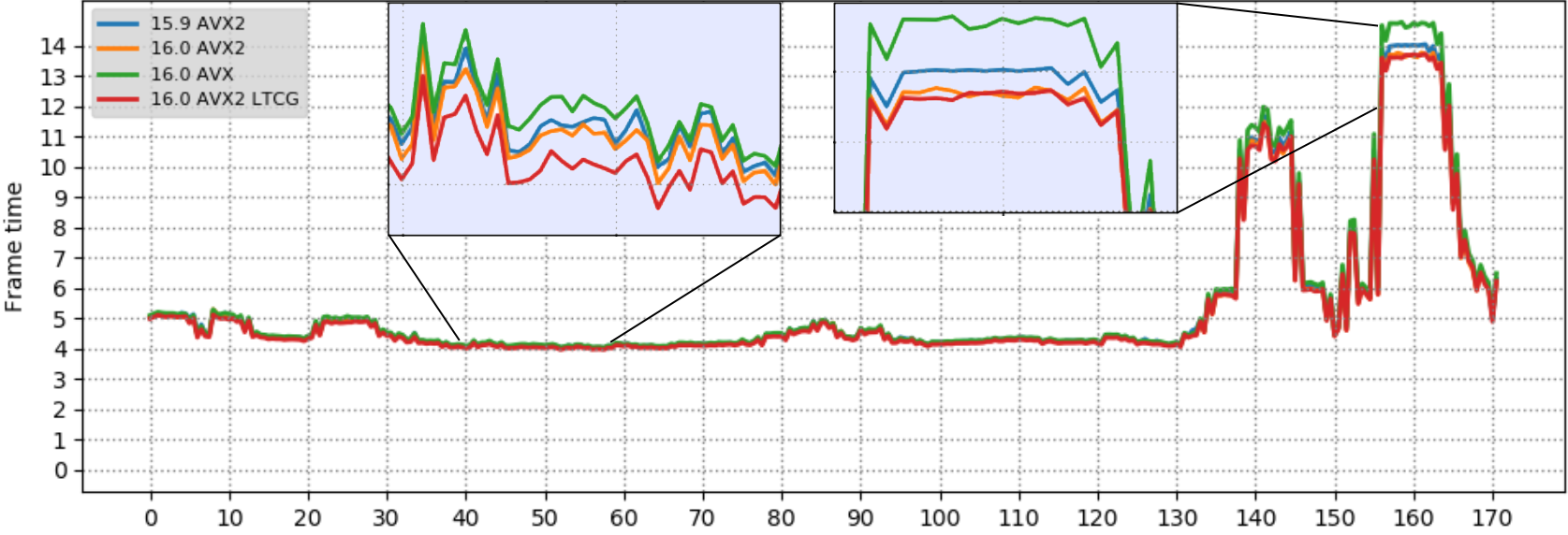
下表总结了整个游戏的平均结果,并将重点放在“慢”部分,其中可以看到最大的改进:
|
改进 |
VS 2019 AVX2 与2017年相比AVX2 | VS 2019 LTCG AVX2 与2019 AVX2对比 | VS 2019 AVX 与2019 AVX2对比 |
|
平均 |
0.7%% |
0.9%% |
-1.8%% |
| 最大的 | 2.8%% | 3.2%% |
-8.5%% |
- 与2017年相比,VS 2019将帧时间提高了2.8%
- 与默认的unity构建相比,LTCG构建将帧时间提高了3.2%
- 在AVX上使用AVX2显示出显著的帧时间改进,高达8.5%,这在很大程度上是由于编译器为标量(现在是16.0)向量操作自动生成FMA指令。
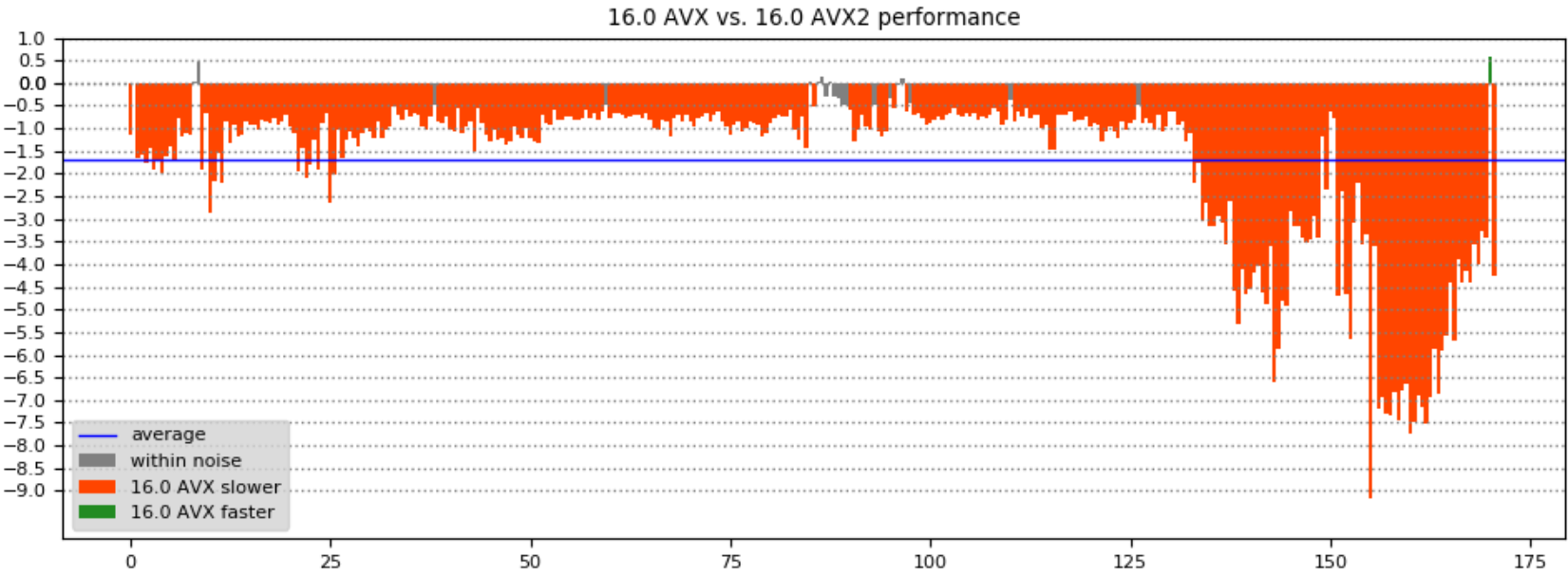
通过计算一个构建相对于另一个构建的加速比(以百分比表示),可以更容易地看到游戏不同部分的性能。下表显示了比较16.0/15.9和AVX/AVX2版本的帧时间时的结果–X轴是游戏中的时间,Y轴是帧时间改进百分比: 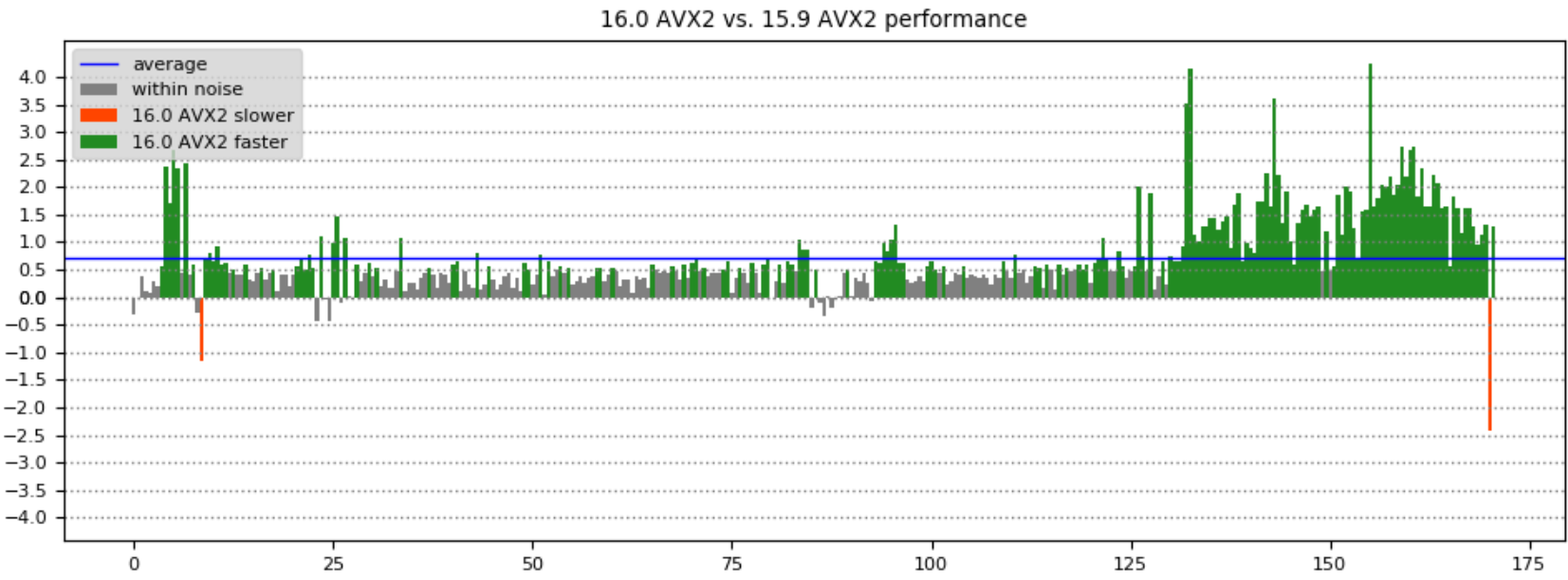
更多优化
除了向量指令优化,VS 2019有几种新的优化,既有助于游戏又有助于C++程序:
- 在其他一些情况下,无用的结构/类副本正在被删除,包括输出参数和返回对象的函数的副本。这种优化在以值传递对象的C++程序中特别有效。
- 添加了一个更强大的分析,用于从控制流(if/else/switch语句)中提取有关变量的信息,用于删除可以证明总是正确或错误的分支,并改进变量范围估计。
- 展开的等长内存集现在将使用16字节的存储指令(或32字节的存储指令)/arch:AVX).
- 文中给出了几种新的标量FMA模式/arch:AVX2. 其中包括以下常用表达式:(x+1.0)*y(x–1.0)*y(1.0–x)*y(-1.0–x)*y。
- 更全面的后端改进列表可以在这里找到 博客文章 .
我们希望你能 下载Visual Studio 2019 试试看。一如既往,我们欢迎您的反馈。我们可以通过下面的评论或电子邮件联系我们( visualcpp@microsoft.com ). 如果您在使用visualstudio或MSVC时遇到问题,或者有什么建议,请告诉我们 帮助>发送反馈>报告问题/提供建议 在产品中,或通过 开发者社区 . 你也可以在Twitter上找到我们( @视觉 )和Facebook(msftvisualcpp)。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)