对于这篇文章,我们欢迎来自英特尔公司的johnmorgan作为visualstudio博客的客座作者。约翰在英特尔工作了9年,但他对微软编译器的贡献可以追溯到20年前以及其他三家公司。他非常感谢英特尔和微软的其他人对这篇文章的帮助。
这篇文章探讨了英特尔® 先进的向量扩展512(英特尔AVX-512),以及它们如何在微软Visual Studio 2017中支持,特别是在微软Visual C++、微软宏汇编程序(MASM)和微软VisualStudioIDE调试器中,以及用于向量计算的典型应用,如人工智能/机器学习,多媒体编码和解码,以及高性能计算工作负载,如模拟和气候/天气建模。
介绍
微软和英特尔® 都在做改变的事。通过改变电脑的功能,我们改变了人们对电脑的功能,这也改变了人们的生活。这种变化的一个重要部分是能够处理更大的计算,以获得比以往任何时候都更具可操作性的见解,因此智能数据检索和自动驾驶等任务都是科学,而不仅仅是科幻小说。为了满足更多数据计算的需求,英特尔推出了新一代英特尔AVX-512系列指令® 至强® 处理器和一些新的英特尔® 核心™ X系列桌面处理器,以及当前的英特尔® 至强融核™ 处理器。Microsoft Visual Studio 2017支持Intel AVX-512,通过Visual Studio 2017 15.3版,我们正在增强这种支持,以包含比以往更多的Intel AVX-512指令。
矢量计算
Intel AVX-512提高了矢量计算的标准。与前面的“英特尔高级向量扩展”(英特尔AVX)指令集扩展一样,“英特尔AVX-512”允许一条指令同时对多个值执行计算,顾名思义,它将此功能一次扩展到512位。然而,这并不是它的全部功能。新特性使以前不实用的计算变得容易。掩蔽允许您矢量化条件代码,嵌入式广播允许您在计算中直接使用标量值,嵌入式舍入控制允许您控制特定指令上的舍入或异常,而无需更改控制寄存器,而新指令执行的计算可能以前需要几十条指令。这些新的和增强的功能对于机器学习(人工智能)以及音频和视频压缩等工作负载以及模拟等经典HPC工作负载非常重要。
机器学习包括创建网络的训练和使用部署的网络,在这两个步骤中都可以使用具有各种数据类型的向量计算。Intel AVX-512支持各种整数和浮点类型的向量,从双精度浮点到字节大小整数的向量。它还有一组增强的转换指令,允许在平衡性能、准确性和存储效率方面具有更大的灵活性。
矢量计算也用于视频和音频压缩。多媒体压缩通常使用人类感知的某些方面来丢弃不需要的数据,并允许数据流减少到未压缩大小的一小部分。大多数这样做的计算可以通过向量运算来完成。最流行的格式通常有特殊的硬件支持,但是一般的向量计算可以用于不太常见的和未来的格式。
最重要的高性能计算(HPC)工作流也使用向量计算完成。这些包括天气和气候建模、地震学、油气勘探、医学成像等。Intel AVX-512为执行此类任务提供了灵活方便的功能。
什么是Intel AVX-512?
英特尔AVX-512有一套基本指令和指令格式,并为特殊目的增加了几套指令,总计约700条新的和修改过的指令。这些指令处理基本的算术运算、类型转换和更专门的操作。随着计算市场的变化和新操作的需要,新的英特尔AVX-512指令集扩展可能会被添加以满足这些需求。Microsoft Visual Studio对这些扩展的支持将建立在Microsoft Visual Studio 2017中Intel AVX-512的基础支持之上。
有关Intel AVX-512的更多信息,请访问 https://www.intel.com/content/www/us/en/architecture-and-technology/avx-512-overview.html ,第1卷和第2卷 英特尔® 64和IA-32体系结构软件开发人员手册 .
Visual Studio 2017年
那么,Microsoft Visual Studio 2017 15.3版究竟让您如何处理Intel AVX-512?英特尔AVX-512支持最重要的部分是微软Visual C++,其中可以定义512位向量变量,将它们的值分配给同一类型的其他变量,并将它们传递给函数,作为函数和返回值。在当前发布的英特尔处理器中,有1300多个新的内部函数与“英特尔AVX-512”指令相对应,包括默认值为零的掩蔽、指定默认值的掩蔽,以及在适用的情况下嵌入舍入或异常控制。这些函数包括512位向量运算,以及大多数AVX-512指令的标量运算。支持128位和256位向量运算,并计划在未来版本中提供额外的标量函数。使用内在函数需要程序员学习如何使用它们以获得最佳效果,但它提供了比自动代码生成更好的控制。Microsoft Visual Studio 2017还包括对Microsoft Visual Studio IDE调试器中的Intel AVX-512和Microsoft linker(dumpbin)的支持。除此之外,Visual Studio 2017 15.3版还增加了对Microsoft宏汇编程序(MASM)中700多条新的和修改的Intel AVX-512指令的支持。
例子
让我们看一个例子,首先是基本的英特尔AVX-512指令,然后是等效的C代码。以下是选择的快速排序透视函数的一个版本,因为它很适合演示Intel AVX-512的功能。此函数接受一个名为 枢轴 和输入列表,并将该列表分为大于轴的值列表和小于轴的值列表。输出列表是连续的,这样就不必整理最终的输出。此变体对另一个表中引用单精度浮点值(可以嵌入较大对象)的索引列表进行排序。索引是32位的倍数,因此它们必须乘以4才能得到比较值的字节偏移量。
现在,当您看到这个例程的汇编语言版本中的向量处理循环时,不要眼花缭乱,因为理解重要的部分并不难。
; RBX points to array of values; RCX is number of elements; RSI points to incoming array of dword indices; RDI points to outgoing array of dword indices; RAX is set to the upper end of the outgoing indices; RDX is used as a temporary register; ZMM30 contains the pivot value in all elementsvector_loop: ; load next 16 indices vmovdqu32 zmm1, zmmword ptr [rsi] add rsi, 64 ; gather comparison values kxnorw k1, k1, k1 ; set 16 mask bits in K1 vgatherdps zmm2 {k1}, [rbx + 4 * zmm1] ; compare with pivot value vcmpltps k1, zmm2, zmm30 {sae} ; store indices for values below pivot vpcompressd [rdi] {k1}, zmm1 ; count how many values were stored kmovw edx, k1 popcnt edx, edx ; move pointers by number of elements stored at ; the beginning and end of output table lea rax, [rax + 4 * rdx - 64] lea rdi, [rdi + 4 * rdx] ; store offsets for values >= pivot knotw k1, k1 vpcompressd [rax] {k1}, zmm1 ; check if can process 16 more elements sub rcx, 16 ; subtract elements we intend to process jnb vector_loop ; if enough left go process them
AVX-512矢量指令指定矢量元素的大小
第一条指令是 VMOVDQU32型 . 此指令将16个dword索引加载到ZMM1中,ZMM1是一个512位向量寄存器,与YMM1共享其低256位。类似于 VMOVDQU公司 ,但指定输入是32位整数的向量。在本例中,这并不重要,但对于掩蔽来说很重要,稍后将对此进行解释。
聚集和分散掩蔽
下一条AVX-512指令使用 克斯诺尔 设置掩码寄存器的低16位 k1级 . 这个习惯用法类似于从寄存器本身减去一个值得到一个零值,但是补全后得到1位。掩码寄存器用于选择向量的哪些元素将被操作。在这种情况下: VGA和DPS 指令将在16个元素上运行,因此它需要一个设置了16位的掩码。掩蔽对于大多数AVX-512指令是可选的,但是聚集和分散指令是特殊的,因为它们在加载或存储值时清除掩蔽中的位,这允许它们在执行之前被中断时恢复。在AVX2中引入了Gather,这些指令基于带有向量分量的地址加载向量元素,在本例中是ZMM1。它从基寄存器(如果指定)、向量索引元素和常量偏移量之和的地址加载每个元素。分散指令类似,只是它们存储值而不是加载值。还有一些特殊的指令,用于检查分散指令是否会尝试将多个值写入同一地址。因为只能存储一个值,所以这将是一个错误,并且可能表示需要考虑依赖关系。
嵌入式异常抑制和舍入控制
以下说明是 VCMPLTPS公司 ,如果gather指令加载的相应值小于ZMM30中的pivot值,则设置K1中的低16位。请注意,在64位模式下,EVEX编码指令最多可以使用32个向量寄存器,而不是为AVX和SSE提供的16个寄存器。此指令还指定“{sae}”作为“抑制所有异常”,这意味着来自比较的任何异常都将被抑制,即使它们没有在浮点控制寄存器中被屏蔽( MXCSR公司) . 比较不会生成浮点结果,但许多指令会生成,对于可能需要对结果进行舍入的大多数AVX-512指令,可以指定如下舍入模式:“{rz sae}”。“rz”表示将结果向零舍入(截断),但也可以指定向上、向下或向最近的可表示值舍入(指定舍入模式时,将抑制异常。)
嵌入式广播
只能为没有内存源操作数的全长向量操作指定异常抑制和嵌入式舍入控制。还有一个只能为内存操作数指定的选项,它是嵌入广播的。向量计算通常具有必须应用于每个向量元素的标量操作数,例如示例中的枢轴值。可以使用如下指令将这些值加载到寄存器中 VBRoadcasts公司 如示例中所示,但是嵌入式广播允许直接从内存使用这些值。例如,如果RBP指向透视值,则此指令可以进行比较:
vcmpltps k1, zmm2, dword bcst [rbp]
“bcst”关键字表示引用值是一个标量,应该广播到操作的向量中。如果引用是从中提取值的向量值的值列表,则将使用传统的内存引用语法:
vcmpltps k1, zmm2, dword ptr [rbp]
“bcst”关键字用于区分标量引用和向量引用,尽管非Microsoft工具可以通过其他方式来实现这一点。
VPCOMPRESSD和更多关于掩蔽的信息
比较后的说明是 VPD压缩 ,仅存储与设置的掩码位对应的向量元素。这些索引对应于小于透视值的值,因此它们存储在输出列表的开头。 VPD压缩 不清除掩码值,因此如果要再次使用它,则不必复制它。请注意,这条指令完成了构建输出列表的大部分工作。使用SSE或AVX指令没有类似的方法来实现这一点。
完成循环
以下两个说明 克莫夫 和 POPCNT公司 计算与一起存储的元素数 VPD压缩 因此可以更新指向输出缓冲区的头和尾指针,这就是下两个 利亚 说明确实如此(我正在预递减输出指针,因为 V压缩 存储从低地址到高地址的值。)
最后, 纽特 反转掩码位,然后 VPD压缩 使用反转掩码将剩余索引存储在输出列表的尾部。然后剩下的就是重复,直到没有另一个完整的向量值来处理。
总共有14条指令来处理16个值,没有不可预测的分支。由于无法使用AVX或SSE指令对该循环进行矢量化,因此只能与标量代码进行比较,标量代码需要10条指令(包括不可预测的分支)才能完成一个值。
C代码中的示例
您可能不想使用汇编语言来编写代码。您可能希望用高级语言编写代码,所以让我们看看这个函数在C中可能是什么样子。
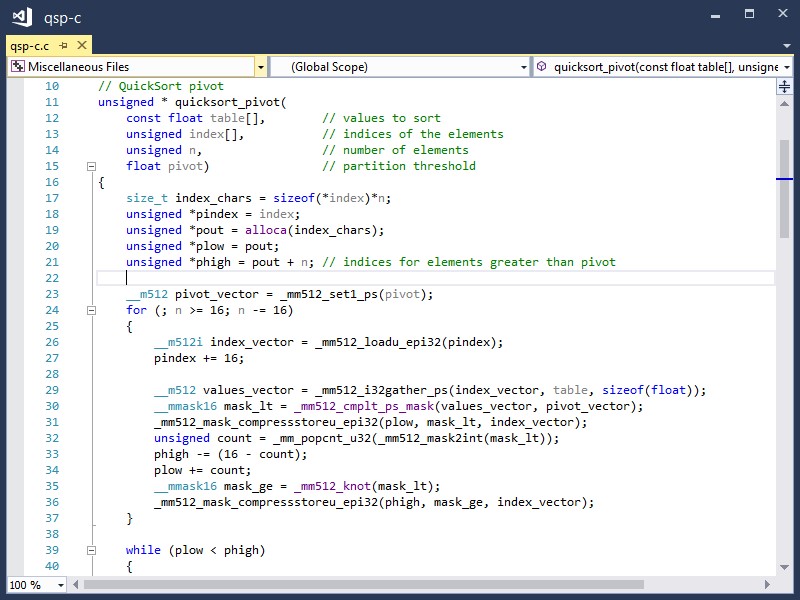
如果将其与汇编语言版本进行比较,您将看到所调用的向量函数与Intel AVX-512指令密切对应。这个 _mm512加载 epi32 函数对应于 VMOVDQU32型 , _mm512u i32收集u ps 对应于 VGA和DPS ,等等。您可以使用 英特尔内部函数指南 网站或第二卷 英特尔® 64和IA-32体系结构软件开发人员手册 . 英特尔VX+C++中的AVX-512功能的声明在 zmmintrin.h公司 当您包含 内啡肽h 或 免疫素h .
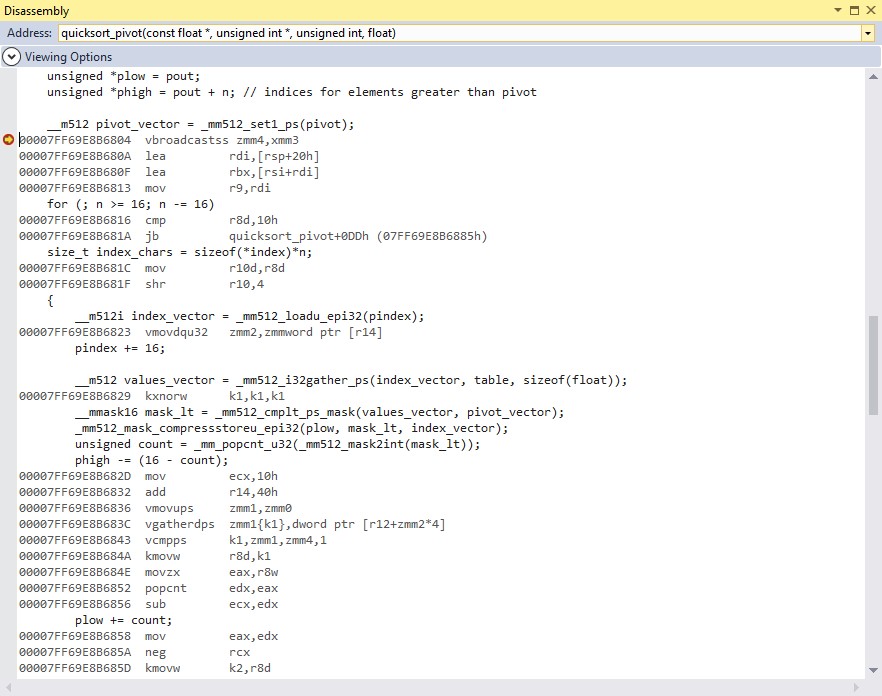
AVX-512指令的反汇编
在执行到 _mm512设置1 ps 函数并打开反汇编窗口(下图),您可以看到C代码生成的指令与上面显示的汇编语言版本相似,但不完全相同。
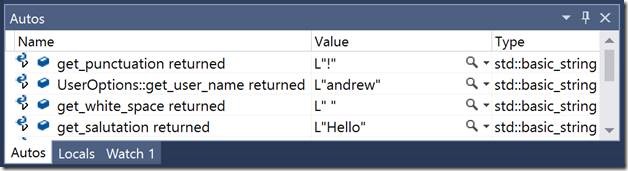
检查向量寄存器
能够查看512位向量值比查看Intel AVX-512指令有用得多。假设你想看看 索引向量 和 值u向量 之后的变量 _mm512u i32收集u ps 函数调用。您可以在下面的监视窗口中看到这些值。
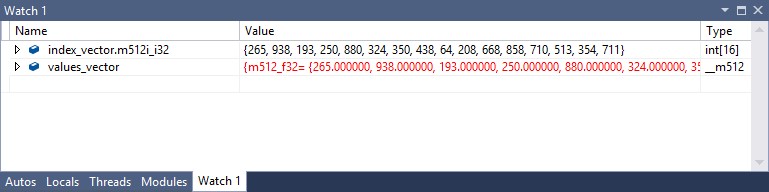
您可以通过右键单击变量名来设置每个变量的监视,就像您对任何其他变量所做的那样。你会注意到 索引向量 由“.m512iu i32”进一步限定,而 值u向量 不是。这个 __m512i型 类型是向量与元素的并集,这些元素可以是8到64位的整数,也可以是有符号的或无符号的,因此为了确保看到实际值,可以通过单击展开箭头并选择m512iu i32选项来指定32位元素。的基本元素类型 __m512型 是单精度浮点,因此不需要选择显示类型 值u向量 . (浮点向量值与索引值匹配是因为它们是以这种方式初始化的,而不是因为它们需要匹配。)除了“监视”窗口外,您还可以在所有预期位置(如局部变量和寄存器值窗口)查看512位向量值。
展望未来
在Visual Studio 2017版本15.3中,我们在微软Visual C++中实现了1500多个英特尔AVX-512内部功能,我们还有更多的工作要做。可用函数主要用于512位向量或浮点标量值。我们计划在即将发布的版本中为256位和128位向量以及浮点标量添加更多函数,这将使AVX-512函数的可用数量增加一倍以上。我们还计划在几个版本中对新的AVX-512特性进行许多额外的优化。
你对我们的计划也很重要,所以请继续关注!在未来的博客文章中,我们将深入探讨英特尔 AVX-512,并用visualstudio编译的例子说明了它的性能优势。一如既往,我们对您的反馈很感兴趣。将您的评论和要求张贴在下面 Visual Studio用户语音 .
谢谢!
免责声明
提供的示例代码仅用于说明目的,并不暗示性能或适用于任何其他目的。
英特尔 技术的特点和好处取决于系统配置,可能 需要启用的硬件、软件或服务激活。性能各不相同 取决于系统配置。 请咨询您的系统制造商或 零售商或了解更多信息 https://www.intel.com .
Intel、Intel徽标、Intel Core、Intel Xeon和Intel Xeon Phi是 英特尔公司在美国和/或其他国家/地区的商标或注册商标。 *微软、VisualStudio和Visual C++是微软公司在美国和/或其他国家的商标或注册商标。其他名称和品牌可被称为 其他人。 © 2017英特尔公司

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.cppku.com/wp-content/themes/zibll/img/thumbnail.svg)