apachekafka是一个分布式流媒体平台。让我们更详细地解释一下。apachekafka是发布和订阅记录流的三个关键功能,类似于消息队列或企业消息传递系统。apachekafka提供了一个分布式的发布-订阅消息传递系统和健壮的队列,可以处理大量的数据,使我们能够传递消息。
阿帕奇·卡夫卡优势
apachekafka为所有者提供了很多好处,但其中一些好处在下面列出的地方非常重要。
-
Reliability是由Kafka提供的,因为它是分布式的、分区的、复制的和容错的。 -
Scalability由Kafka提供,无停机时间。 -
Durability由Kafka提供,消息尽可能快地保存在磁盘上。 -
Performance由Kafka提供,其中有大量的消息用于发布和订阅。 它可以提供稳定的性能与事件TB的消息存储。
下载并安装Kafka For Linux和Windows
我们可以将apachekafka安装到Linux、Ubuntu、Mint、Debian、Fedora、CentOS和Windows操作系统中,其中Kafka是基于Java的软件。如果我们能在这些操作系统中安装Java,我们就可以很容易地运行Kafka。
下载Apache Kafka
我们将从以下链接下载apachekafka。这个链接为我们提供了最近的镜像下载。
https://www.apache.org/dyn/closer.cgi?path=/kafka/2.2.0/kafka_2.12-2.2.0.tgz公司

在本例中,我们将使用 wget 命令。
$ wget http://kozyatagi.mirror.guzel.net.tr/apache/kafka/2.2.0/kafka_2.12-2.2.0.tgz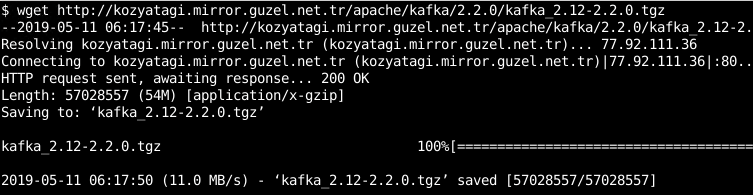
提取下载的文件
我们将用 tar 命令如下。
$ tar xvf kafka_2.12-2.2.0.tgz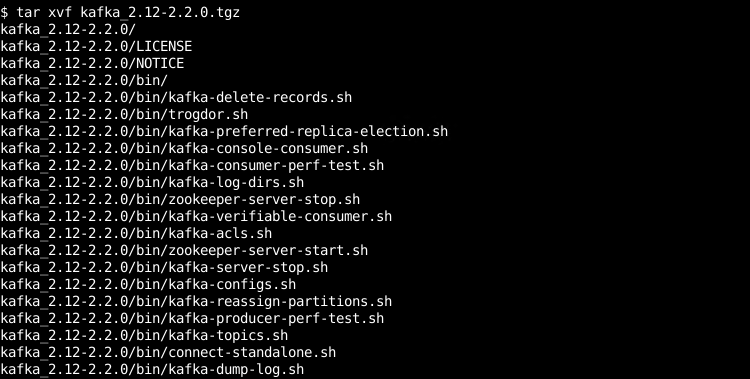
我们将进入解压目录
$ cd kafka_2.12-2.2.0/启动ZooKeeper服务器
阿帕奇·卡夫卡由动物园管理员管理。因此,为了启动Kafka,我们将使用提供的配置启动ZooKeeper服务器。我们将使用 zookeeper-server-start.sh 通过提供提供的默认配置来创建bash脚本 zookeeper.properties .
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties
启动Kafka服务器
现在我们可以使用 kafka-server-start.sh 配置文件名为 server.properties .
$ ./bin/kafka-server-start.sh ./config/server.properties
我们将在控制台消息中看到如下配置。
创建主题
我们可以用 kafka-topics.sh 创建名为 poftut .
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic poftut 然后我们可以用 --list 参数如下。
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
发送一些消息
我们可以用 kafka-console-consumer.sh 就像下面一样。
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic poftut
启动消费者
我们可以使用 kafka-console-consumer.sh 就像下面一样。
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic poftut --from-beginning
ApacheKafka用例
apachekafka可以在不同的情况下使用。在这一部分,我们将列出其中最方便、最受欢迎的。
信息
Kafka可用于messagebroker。Kafka被设计成健壮、稳定、高性能的消息传递。 与大多数消息传递系统相比,Kafka具有更好的吞吐量、内置的分区、复制和容错能力,是一种从小型到大型消息处理应用的很好的解决方案。
相关文章: 如何在Fedora、CentOS、RHEL Linux上安装Apache2.4和PHP7.3?
网站活动跟踪
Kafka的原始用例能够将用户活动跟踪管道重建为一组实时发布订阅提要。活动跟踪通常是高容量的,因为每个用户页面视图都会生成许多活动消息。
韵律学
卡夫卡可以作为作战数据监控。这涉及到跟踪和分发度量到不同的生产者和消费者,如网络,移动,桌面。
日志聚合
日志聚合是一项很难完成的工作。Kafka可以用于来自不同生产者和发送者的日志聚合,以集中收集它们,并提供其他日志组件,如SIEM、log Archiver等。
流处理
apachekafka可以轻松地处理流数据。流处理可以在多个阶段完成,其中输入的原始数据可以聚合、丰富或转换为新主题以供进一步使用。
提交日志
Kafka可以作为分布式系统的外部提交日志。日志可用于在节点之间复制数据,并充当重新同步机制。
Apache-Kafka体系结构
从用户的角度来看,apachekafka有一个非常简单的体系结构。卡夫卡系统中有不同的参与者用于创建、连接、处理和使用数据。
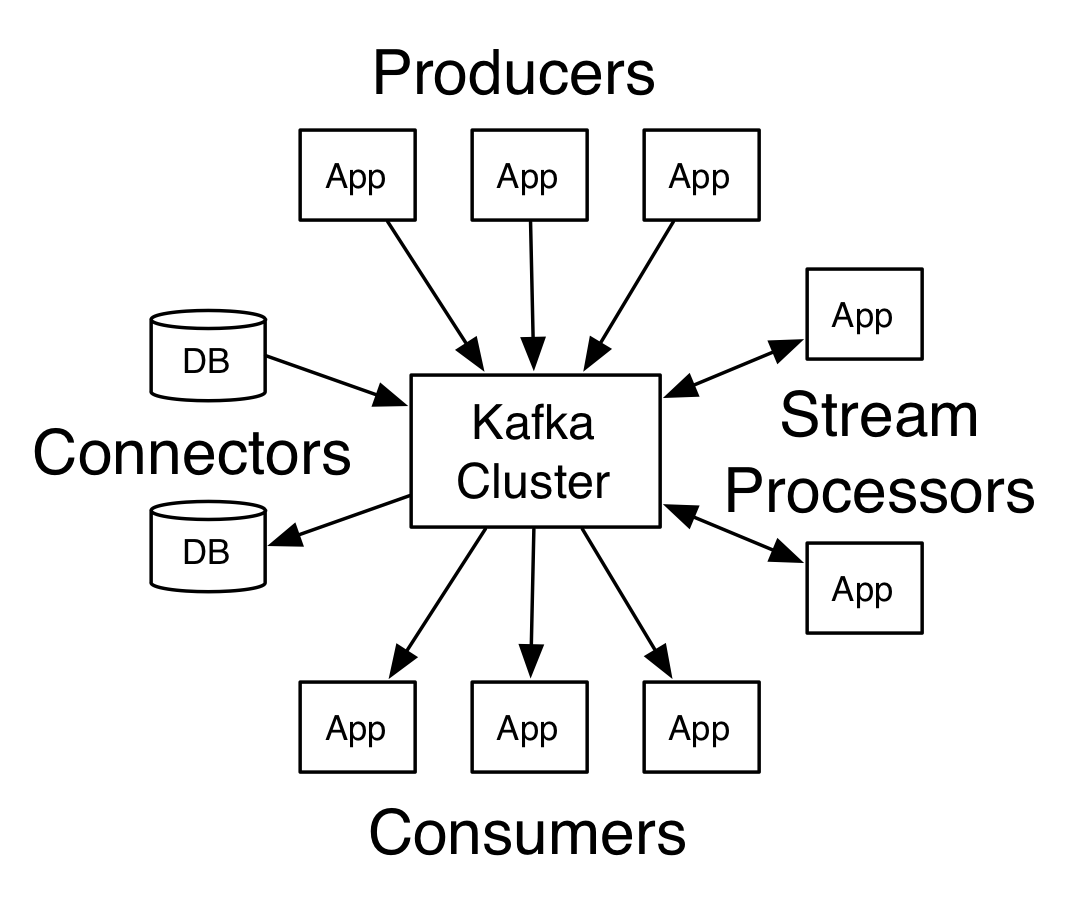
生产者
生产商将创建数据,并通过不同的方式(如API)将这些数据提供给Kafka系统。生产者还使用不同的编程语言SDK和库来推送他们创建的数据。
连接器
连接器用于在ApacheKafka和其他系统之间创建可伸缩和可靠的数据流。这些系统可以是数据库、文件系统等。
相关文章: 如何在Apache和Nginx中将Http重定向到Https
流处理器
在某些情况下,应处理或转换输入数据。流处理器用于处理和转换不同的主题和输入数据,并输出到不同的主题或消费者。
消费者
消费者是主要获取、使用、消费卡夫卡提供的数据的实体。消费者可以使用不同主题的数据,这些数据可以被处理,也可以不被处理。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)